seleniumでマネーフォワードをスクレイピング、LINEへ通知する

今月の請求額を各サイトからスクレイピングして、「引き落とし口座にいくら入金すればいいのか」を毎月LINEに通知するシステムを構築中。
楽天カードの請求額をスクレイピングして、LINE Notifyで通知するところまで設定しました。
今回は、楽天カードのほか、以下の項目を取得して通知するロジックを作っていきます。
スクレイピングで自然派コープの請求額を取得
我が家で注文している、コープの請求額を取得します。
コープは、毎月18日ごろに請求額が出てくるので、20日前後に取得させたほうがよさそう。
def get_corp_bill(): username = 'xxxxx' password = 'xxxxxxx' target_url = 'https://www.shizenha.ne.jp/shizenha_online/' error_flg = False options = Options() options.add_argument('--headless') driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) driver.get(target_url) sleep(3) # login try: username_input = driver.find_element_by_xpath("//input[@name='LoginCode']") username_input.send_keys(username) sleep(1) password_input = driver.find_element_by_xpath("//input[@name='Password']") password_input.send_keys(password) login_button = driver.find_element_by_xpath("//a[@id='btnLogin']") login_button.click() sleep(1) except Exception: error_flg = True print('ユーザー名、パスワード入力時にエラーが発生しました') driver.close() driver.quit() pass # 請求書ページを開く if error_flg is False: try: driver.get('https://www.shizenha.ne.jp/shizenha_online/Main/Mypage') sleep(3) notnow_button = driver.find_element_by_xpath("//a[text()='オンライン請求書照会']") notnow_button.click() sleep(3) except Exception: print('buttonエラーが発生しました') # 例外の場合、処理をしない pass driver.close() driver.quit() pass soup = BeautifulSoup(driver.page_source,'html.parser') elms = soup.select('body table.bill_list') df = pd.read_html(str(elms))[0] df = df.drop(df.columns[[0,3]], axis=1) df.columns = ['請求月','支払総額'] latests = { "month" : df['請求月'][0], "bill" : int(df['支払総額'][0].replace(',','').replace('円','')) } driver.close() driver.quit() return latests
マネーフォワードの口座情報を自動で更新
マネーフォワードの無料会員だと、それぞれの口座ごとに「更新」ボタンを押さないと口座情報が更新されません。
ついでなので、登録されている口座を一気に更新しておきます。

# FWにログイン 口座情報を更新 def fw_reloaded_bank(): username = 'email@example.com' password = 'xxxxxxxxxxxxxxxxxx' assets = {} options = Options() options.add_argument('--headless') # headlessモードを使用する options.add_argument('--disable-gpu') # headlessモードで暫定的に必要なフラグ(そのうち不要になる) options.add_argument('--disable-extensions') # すべての拡張機能を無効にする。ユーザースクリプトも無効にする options.add_argument('--proxy-server="direct://"') # Proxy経由ではなく直接接続する options.add_argument('--proxy-bypass-list=*') # すべてのホスト名 options.add_argument('--start-maximized') # 起動時にウィンドウを最大化する options.add_argument('--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36') # UserAgentを偽装する driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) # login driver.get("https://id.moneyforward.com/sign_in/email") driver.implicitly_wait(10) # 秒 driver.find_element_by_xpath("//input[@name='mfid_user[email]']").send_keys(username) driver.implicitly_wait(5) # 秒 driver.find_element_by_class_name("submitBtn").click() driver.implicitly_wait(10) # 秒 driver.find_element_by_xpath("//input[@name='mfid_user[password]']").send_keys(password) driver.implicitly_wait(5) # 秒 driver.find_element_by_class_name("submitBtn").click() driver.implicitly_wait(10) # 秒 driver.get('https://moneyforward.com/accounts/show/zxc8ekTu_VM7A8bTRaI3cg') driver.implicitly_wait(20) # 秒 driver.find_element_by_xpath("//input[@type='submit']").click() driver.implicitly_wait(10) # 秒 driver.get("https://moneyforward.com/accounts") elms = driver.find_elements_by_xpath("//input[@data-disable-with='更新']") for elm in elms: elm.click() sleep(1)
seleniumでマネーフォワードから引落とし口座の残高を取得
マネーフォワードにログインできたので、ポートフォリオのページから、引き落とし用の口座の残高、ついでに合計資産を取得してきます。
# カード引き落とし口座の残高、合計資産を取得 def fw_get_assets(): username = 'email@example.com' password = 'xxxxxxxxxxxxxxxxxx' assets = {} options = Options() options.add_argument('--headless') # headlessモードを使用する options.add_argument('--disable-gpu') # headlessモードで暫定的に必要なフラグ(そのうち不要になる) options.add_argument('--disable-extensions') # すべての拡張機能を無効にする。ユーザースクリプトも無効にする options.add_argument('--proxy-server="direct://"') # Proxy経由ではなく直接接続する options.add_argument('--proxy-bypass-list=*') # すべてのホスト名 options.add_argument('--start-maximized') # 起動時にウィンドウを最大化する options.add_argument('--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36') # UserAgentを偽装する driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) # login driver.get("https://id.moneyforward.com/sign_in/email") driver.implicitly_wait(10) # 秒 driver.find_element_by_xpath("//input[@name='mfid_user[email]']").send_keys(username) driver.implicitly_wait(5) # 秒 driver.find_element_by_class_name("submitBtn").click() driver.implicitly_wait(10) # 秒 driver.find_element_by_xpath("//input[@name='mfid_user[password]']").send_keys(password) driver.implicitly_wait(5) # 秒 driver.find_element_by_class_name("submitBtn").click() driver.implicitly_wait(10) # 秒 driver.get('https://moneyforward.com/accounts/show/zxc8ekTu_VM7A8bTRaI3cg') driver.implicitly_wait(20) # 秒 driver.find_element_by_xpath("//input[@type='submit']").click() driver.implicitly_wait(10) # 秒 # カード引き落とし口座の残高 soup = BeautifulSoup(driver.page_source,'html.parser') assets["card_bank"] = soup.find('h1',{'class':'heading-small'}).text assets["card_bank"] = int(assets["card_bank"].replace('資産総額:','').replace(',','').replace('円','')) driver.implicitly_wait(20) # 秒 # 合計資産 driver.get('https://moneyforward.com/bs/portfolio') sleep(5) soup = BeautifulSoup(driver.page_source,'html.parser') elms = soup.select('section.bs-total-assets table') df = pd.read_html(str(elms))[0] df = df.T.drop(0,axis=0).drop(2,axis=0) df.columns = ['預金合計資産','投資信託'] df['預金合計資産'][1] = df['預金合計資産'][1].replace(',','').replace('円','') df['投資信託'][1] = df['投資信託'][1].replace(',','').replace('円','') df = df.astype('int') df['預金合計資産'][1] + df['投資信託'][1] assets["bank"] = df['預金合計資産'][1] assets["stock"] = df['投資信託'][1] assets["assets_all"] = df['預金合計資産'][1] + df['投資信託'][1] driver.close() driver.quit() return assets
LINE Notifyへ通知する
それぞれのスクレイピング→通知までできるか、テストしてみます。 残高が足りなかった場合とメッセージをだし分け、いくら残高が不足しているのかをわかりやすくします。
def cal_billing(): rakuten = get_rakuten_bill() corp = get_corp_bill() assets = fw_get_assets() bill_home = 85000 # 家賃 # 合計請求額 bill_all = rakuten + corp['bill'] + bill_home # 差額 cal_billing = assets['card_bank'] - bill_all cal_price = '' if cal_billing < 0: cal_price = f'▷ {cal_billing * -1}円足りません' else: cal_price = f'▷ 引き落とし後の残高は{cal_billing}円です' messages = f""" 〜〜今月の請求額のお知らせ〜〜 ■請求金額合計: {bill_all}円 --------- ・カ ー ド: {rakuten}円 ・自 然 派: {corp['bill']}円 ・住 居 費: {bill_home}円 --------- ■口座残高: {assets['card_bank']}円\n {cal_price}\n ■資産状況 --------- 預金資産: {assets["bank"]}円 投資信託: {assets["stock"]}円 資産合計: {assets["assets_all"]}円 ----------------- """ return messages if __name__ == "__main__": notify_message(cal_billing())
結果

無事、スクレイピング結果を通知できました!!
当初の目的であった「引き落とし用口座にいくら入金すればいいか」が簡単にわかる仕組みができたので万々歳です。
一応さらにリファクタリングしてから使ってみようと思います。 定期実行は、、Webサーバーに置くとseleniumの動作が不安なので、ローカルで実行させるつもり。
【Python】楽天カードの請求確定額をLINE Notifyで通知してみた
カード請求額を毎回チェックするのは面倒なので、LINE Notifyで通知する仕組みを構築中です。
今回まとめるのは以下の部分
最終的に、マネーフォワードから銀行の口座残高や資産状況を取得してきて、毎月の資産を把握できるようにしようかと思っています。
今回はその前段部分です。
楽天カードから請求額をスクレイピング
from selenium import webdriver from selenium.webdriver.chrome.options import Options import requests from bs4 import BeautifulSoup import pandas as pd from time import sleep from datetime import datetime def get_rakuten_bill(): # password USERNAME = 'email@example.com' PASSWORD = 'xxxxxxxxxxxxxxxxx' error_flg = False # open chrome options = Options() options.add_argument('--headless') driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) target_url = 'https://www.rakuten-card.co.jp/e-navi/index.xhtml' driver.get(target_url) sleep(3) # login try: username_input = driver.find_element_by_xpath("//input[@name='u']") username_input.send_keys(USERNAME) sleep(1) password_input = driver.find_element_by_xpath("//input[@name='p']") password_input.send_keys(PASSWORD) login_button = driver.find_element_by_xpath("//input[@type='submit']") login_button.submit() sleep(1) except Exception: error_flg = True print('ユーザー名、パスワード入力時にエラーが発生しました') # 請求書ページを開く if error_flg is False: try: driver.get('https://www.rakuten-card.co.jp/e-navi/members/statement/index.xhtml?tabNo=1&l-id=enavi_top_info-card_statement') sleep(3) except Exception: print('エラーが発生しました') # 例外の場合、処理をしない pass pass # 最新の請求額を取得 try: soup = BeautifulSoup(driver.page_source,'html.parser') billing_latest = int(soup.find('span',{'class':'stmt-u-fs-xxl'}).text.replace('\n','').replace(',','')) sleep(1) except Exception: error_flg = True print('エラーが発生しました') # chrome driver close driver.close() driver.quit() return billing_latest
ユーザー名とパスワードはご自身のものに書き換えてください。
楽天カードは、毎月12日に請求額が確定するので、12日以降にスクリプトを実行するようにする予定です。
これで、確定した請求額が取得できます。
LINE Notify で今月の請求額を通知
LINE Notifyはアクセストークンを取得するだけでいいので、とっても簡単に実装できる。

ドキュメントにある、POSTのエンドポイントURLを使用します。
ドキュメント↓ LINE Notify
import requests def notify_message(message): LINE_NOTIFY_TOKEN = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' url = 'https://notify-api.line.me/api/notify' headers = { 'Authorization': f'Bearer {LINE_NOTIFY_TOKEN}' } data = { 'message': message } requests.post( url, headers=headers, data=data )
アクセストークンは直書きしてますが、セキュリティを考慮したい人は別ファイルに記述して読み込ませてください。
テスト
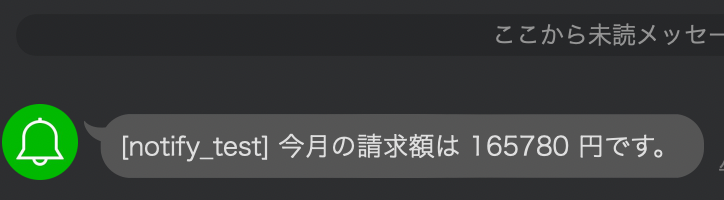
無事、通知できました。
今月の請求額多いな。。。
また続き書きます。
Pythonで中古住宅情報をスクレイピングしてみた
住宅情報サイトを見ていて、1つずつ情報を見るよりも、「データ形式でざっと全体像を把握したい」って思うことがあり、スクレイピングで解決してみた
今回は、 SUUMOから情報を取得してみました。
スクレイピングのコード
BeautifulSoupを使いました。
import requests from bs4 import BeautifulSoup import pandas as pd from time import sleep pages = '1' # 対象URL url = f"https://suumo.jp/jj/bukken/ichiran/JJ012FC001/?ar=060&bs=021&sa=01&ta=27&po=0&pj=1&pc=100&pn={pages}" res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') # 検索結果件数からページ数を算出 post_count = soup.select('div.pagination_set-hit')[0].text post_count = post_count.replace('件', '').replace(',', '').strip() max_page = math.ceil(int(post_count) / 100) # ページ数の数だけループ list_all = [] for page in range(1, (max_page + 1)): pages = page res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') # get htmltag title = soup.find_all('h2') price = soup.select('span.dottable-value') addr = soup.find_all('dt', text='所在地') access = soup.find_all('dt', text='沿線・駅') land_area = soup.find_all('dt', text='土地面積') build_area = soup.find_all('dt', text='建物面積') year_built = soup.find_all('dt', text='築年月') # 取得したページhtmlからタグ取得 # 1ページあたりの表示数は100 なので100でループ処理 for i in range(100): csv_list = [] csv_list = [ title[i].a.string, "https://suumo.jp" + title[i].a['href'], price[i].string.replace('万円',''), addr[i].find_next_sibling().text, access[i].find_next_sibling().text, land_area[i].find_next_sibling().text.split('m')[0], build_area[i].find_next_sibling().text.split('m')[0], year_built[i].find_next_sibling().text, ] list_all.append(csv_list) sleep(10) # リストをユニークに変換 def get_unique_list(seq): seen = [] return [x for x in seq if x not in seen and not seen.append(x)] # dataframeへ格納 header = ['タイトル','URL','価格','所在地','沿線・駅','土地面積','建物面積','築年月'] df = pd.DataFrame(get_unique_list(list_all), columns=header)

こんな感じで、それぞれの住宅情報がデータ形式にできました。
あとは集計するなり分析するなり、いろいろできそう。
やってること
対象URLの部分には、SUUMOでスクレイピングしたい条件で検索し、検索結果で表示された一覧ページを入力します。
結果ページのページ数を数えて、ページ分だけループ処理して取得してきます。
複数の住宅情報サイトからスクレイピングして比較してみるのも面白そうですね。
【Python】スクレイピングでエンジニア言語別給料幅を集計してみた

プログラミング言語って、結局どの言語を選択すれば給料が上がるんだろ? 素朴な疑問から、求人サイトをスクレイピングして集計してみました。
Web業界の求人情報をスクレイピング
— こうへい@データアナリスト (@kei_01011) May 10, 2021
それぞれの言語名をキーワードに情報を取得して前処理
給料をプロットしてみた。
まずは、主なバックエンド言語とFW、データ分析系のキーワードで。
データ分析系のキーワードは給料水準高め📊 pic.twitter.com/lkj0JsRIYj
Web業界の求人情報分析 フロントエンドver
— こうへい@データアナリスト (@kei_01011) May 10, 2021
React と Vue が強い。(Angular忘れてました…)
それと合わせて、TypeScriptがトレンドで給料も高い。
フロントエンドエンジニアならTypeScriptは習得しておきたいところですね🙄 pic.twitter.com/eopZePyOY7
集計方法
GREENの求人サイトから集計
バックエンド、データ分析系、フロントエンドの言語で検索し、それぞれの求人情報のタグ、最低給料、最大給料を取得して集計
コード
import requests from bs4 import BeautifulSoup import pandas as pd from selenium import webdriver from selenium.webdriver.chrome.options import Options from time import sleep def get_green_items(keyword): # driver and beautifulsoup options = Options() options.add_argument('--headless') driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) pages = '1' url = f"https://www.green-japan.com/search_key/01?keyword={keyword}&page={pages}" #html取得 driver.get(url) res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') # 検索結果件数からページ数を算出 post_count = soup.select('.pagers') max_page = int(post_count[0].find_all('a')[5].text) print(max_page) # ページ数の数だけループ| list_all = [] for page in range(1, (max_page + 1)): try: options = Options() options.add_argument('--headless') driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=options) pages = page url = f"https://www.green-japan.com/search_key/01?keyword={keyword}&page={pages}" driver.get(url) res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') print(url) # get htmltag offer = soup.find_all('div',{'class':'job-offer-icon'}) html_salary = soup.find_all('ul',{'class','job-offer-meta-tags'}) company = soup.find_all('h3',{'class':'card-info__detail-area__box__title'}) html_sub_title = soup.find_all('div',{'class':'card-info__detail-area__box__sub-title'}) html_tag_lists = soup.find_all('ul',{'class':'tag-gray-area'}) html_href = soup.find_all('a',{'class':'js-search-result-box'}) # 'https://www.green-japan.com/' + # 取得したページhtmlからタグ取得、CSV吐き出し print(f"{page}page:start...") except: print('error') # 1ページ分のデータをリストに格納 for i in range(10): data_list = [] tags = [] try: # HTMLタグがない場合があるので条件分岐させる salary = html_salary[i].find('span').next_sibling.replace('\n','').replace(' ','').replace('万円','').split('〜') salary_check = html_salary[i].find_all('span',{'class':'icon-salary'}) if len(salary_check) > 0: min_salary = salary[0] max_salary = salary[1] else: min_salary = '' max_salary = '' sub_title = html_sub_title[i].find_all('span') for title in sub_title: if '設立年月日' in title.text: build = title.text.replace('設立年月日 ','').replace('年','/').replace('月','') elif '従業員数' in title.text: staff = title.text.replace('従業員数 ','').replace('人','') elif '平均年齢' in title.text: age = title.text.replace('平均年齢','').replace('歳','') else: pass tag_lists = html_tag_lists[i].find_all('span') url = 'https://www.green-japan.com/' + html_href[i]['href'] for tag in tag_lists: tags.append(tag.text) tag_list = ','.join(tags) data_list = [ company[i].text, offer[i].text, min_salary, max_salary, build, staff, age, tag_list, url ] list_all.append(data_list) time.sleep(5) except: print('page error') pass print(f"{page}page:done...!") time.sleep(8) columns = ['企業名','オファータイトル','給料最小値','給料最大値','設立年月日','従業員数','平均年齢','タグ','URL'] df = pd.DataFrame(list_all,columns=columns) return df
get_green_items('Python')で実行。
今回、seleniumを使ってみたかっただけなので、わざわざseleniumを使う必要はない。
BeautifulSoupで十分収集可能だと思う。
収集したデータはスプレッドシートなりに吐き出して、Tableauで可視化。
今回は、企業の個別情報も含んでいるのでTableauPublicにパブリッシュはしていません。
【Tableau】何が人を幸せにするのか?世界幸福度調査を可視化してみた
世界の幸福度調査を可視化
— こうへい@データアナリスト (@kei_01011) May 16, 2021
何が人を幸せにするのか、どこの国が幸福度が高いのか?#Tableau #happiness_report https://t.co/NabQjz0yEx @tableaupublicより
Kaggleのデータセットの中で、World Happiness Report という世界幸福度調査を見つけ、日本の現状を知るために可視化してみました。
TableauPublic↓
データ出典 World Happiness Report | Kaggle
2019年日本は58位


1位のフィンランドと比べるとこんな感じ
| 項目 | 日本 | フィンランド |
|---|---|---|
| ソーシャルサポート | 1.419 | 1.587 |
| 1人あたりGDP | 1.327 | 1.340 |
| 人生の選択をする自由度 | 0.445 | 0.596 |
| 健康寿命 | 1.088 | 0.986 |
| 寛大さ | 0.069 | 0.153 |
| 汚職の認識 | 0.140 | 0.393 |
特に、「ソーシャルサポート」、「人生の選択をする自由度」」が低かった。
「自分で選択できる自由度」と「人とのつながり」が重要
1位のフィンランドと日本を比べたときに、大きな差を感じるのは「人とのつながり」と「自由度」
自分自身で選んで進路を決定した人は、達成感や自尊心で主観的幸福度が高まると考えられています。
自己決定によって進路を決定した者は、自らの判断で努力することで目的を達成する可能性が高くなり、また、成果に対しても責任と誇りを持ちやすくなることから、達成感や自尊心により幸福感が高まることにつながっていると考えられます。
また、対人関係の幸福度への影響についての研究が散見され、こちらも重要な指標みたいです。
http://www.ias.sci.waseda.ac.jp/GraduationThesis/2011_summary/1w080548_s.pdf
ソーシャルサポートに関しては、親世代との世代間ギャップが大きく、現代の考え方とのミスマッチでなかなかうまく行かないケースも出てきそうです。
北欧エリアの幸福度が高いのはなぜなのでしょうか? GDPについては大差がないのですが、国民のための政策が充実しているのか、、このあたりも深堀りしてみたい。
【Tableau】人口推計を可視化、世界の人口から見る日本の現状

出典データ 『日本の地域別将来推計人口(平成30(2018)年推計)』
こちらの 3. 男女・年齢(5歳)階級別の推計結果一覧(Excel 約8.0MB) を使用
ほとんどの地域が真っ赤で、人口が減少していくエリア。 一部地域、都市部に人口が集中し、地方はとんでもない過疎化になります。
世界の人口推移と比較
主要国の人口推移を可視化してみた
— こうへい@データアナリスト (@kei_01011) May 9, 2021
・人口推移
・生産年齢人口比率
・高齢者人口比率
・若年層比率
世界と比較しても、高齢者の割合が突出してますねhttps://t.co/gaqEcXaDtM pic.twitter.com/9tN1p4FKVY
こちら見ての通り、若者が減り、高齢者が急増していきます。
- 生産年齢人口比率 減少
- 若年層比率 減少
- 高齢者層比率 急増
世界と比較しても、日本の少子高齢化は半端ないってことがわかりました。
家事育児は本当に大変。身に染みた話
しばらく、TwitterやNOTEの発信ができていませんでしたが、ちょっと理由があって、今は家事育児を僕が全てこなしています。
もともと家事は妻と分担していたのですが、一人でやるとなると超大変で、珍しくイライラしちゃったりしました。
リアルの友人でもいるのですが「旦那さんが家事や育児を手伝ってくれない」って人も結構いるようですし、家事育児の大変さを分かってない人が多いのかなーと思ったりしてます。
ちょっと今の僕の状況をまとめておきたいと思います。
妻が妊娠、悪阻でダウン!
そもそも僕が一人で奮闘している理由は、妻の悪阻がひどくて、動けないためです。
1人目の時もある程度悪阻はあったのですが、今回はかなりひどいようで、1日中横になってます。
僕の両親は遠方に住んでいて、協力は得られない、
妻の両親の家は近いのですが、二人ともバリバリ働いているため、全面的な協力は得られそうにないですが、仕事終わりや休日は娘をみてくれているのでとってもとっても助かっています
ちなみに、娘は1歳児です。
具体的に何すんの?
「家事って言っても、料理とか洗濯くらいでしょ?」って思うかもしれませんが、細かいことはたくさんあります。
洗濯と言ってもなめちゃいけません。
「洗濯して、乾燥して、洗濯物を畳んで、収納する」という作業をほぼ毎日続けるのって、めちゃくちゃ大変ですし重労働です。
一人暮らしの経験がない人、未婚、子供がまだいない人には想像できないかもしれません。
具体的なスケジュールはこんなかんじ
平日
・起床
・娘の離乳食準備
・ゴミだす
・娘を起こしてご飯
・歯磨きしてお着替え
・保育園の送迎
・帰ってきたら、片付けして仕事(フルリモート)
・休憩時間(昼食を作る、洗濯をする、妻の食欲があればご飯を作る)
・仕事の合間に抜けて保育園のお迎え
・保育園から帰ったら、服やおむつを洗濯
(ここで義母が娘をみてくれる)
・仕事終わり→娘をお風呂に入れる
・娘を寝かしつける
・自分のご飯作る、食器洗い、片付け
・明日の保育園の準備
・プログラミング学習
・寝る
休日
(休日は基本的に、どちらかの両親がきてくれて、妻と娘をみてくれる)
休日にやること
・買い物
・掃除
・布団を干す
・洗濯
・1週間分の離乳食
・作り置きご飯をまとめて作る
すぐに洗濯物はいっぱいになるし、ご飯も作らなきゃいけない、娘がなかなか寝てくれないなどなど、、とにかく毎日がバタバタで、自分の時間を確保する暇がないほどです。
休日も、掃除、洗濯、料理をしてたら1日が終わる感じですね。
両親の助けがなければ、ぶっ倒れてると思います、本当に感謝。
あと、
朝のご機嫌をとるときとか、ちょっと大人しくして欲しい時には、「いないいないばあっ!」に頼ります。
いつもありがとう、ワンワン。
家事や育児は夫婦でするものでしょ
「最近の旦那は偉いねー、昔は何にも手伝ってくれなかったよ!」
親戚や、両親によく言われるのですが、誰に言われたわけでもなく、二人で生きていこうと決めたのだから当たり前だと思っています。
もし、この記事を読まれているあなたがご結婚されていて、奥さんに家事や育児を全て任せているとしたら、
心の底から感謝して欲しいなーと思うわけです。
1週間でもいいから、全部やってみると大変さが身にしみてわかります。
子供のことは愛しているとはいえ、ずっと家事ばかりしていては息がつまる人もいます。
「たまには息抜きしたら?」って代わってあげるだけでも、とっても助かるので、世の中の旦那さんはどんどん家事や育児に参加して欲しいなーと思いますね。