Githubでチーム開発する際によく使うGitコマンド
issueに着手する際、DraftのPRを出す
issueに着手する際、空のプルリクエストを送る必要がある。
git commit --allow-empty -m "PR Title"プルリクを出した後、ローカルで作業を継続する
main → test1のブランチで作業し、プルリクを出してマージされるのを待っている状態。
そのまま作業を継続する場合。
-
そのまま test1のブランチで実装
-
マージされたら
git stashして実装の差分を退避される -
master を pull して test1 の実装がマージされた最新状態にする
-
新しく test2 ブランチを切って
git stash popを実行して差分を復活させる -
そのまま test2 ブランチで実装を続行して PR 出す
git stash -uで未追跡のファイルもstashできる
#以下どちらでも可能
$ git stash -u
$ git stash --include-untracked
#忘れそうならメッセージも添えられます
$ git stash save -u 'hoge'
# 変更を戻す
$ git stash pop stash@{0}コミットの取り消し、打ち消し、上書き
コミットの取り消し
直前のコミットをなかったことにしたい
git reset --hard HEAD^-
hardオプション:コミット取り消した上でワークディレクトリの内容も書き換えたい場合に使用。 -
softオプション:ワークディレクトリの内容はそのままでコミットだけを取り消したい場合に使用。 -
HEAD^:直前のコミットを意味する。 -
HEAD~{n}:n個前のコミットを意味する。
コミットの打ち消し
作業ツリーを指定したコミット時点の状態にまで戻し、コミットを行う(コミットをなかったことにはせず、逆向きのコミットをすることで履歴を残す)には、
git revert コミットのハッシュ値コミットの上書き
git commit --amend-
コミットメッセージを変更したい時
-
これもコミットに加えたい が後から気づいたとき
-
git rebase失敗した時、コンフリクトを避けるためにコミットを上書きしたり
gitのcommitをまとめる
git log --onelineでログを確認。
426f407 (HEAD -> develop) commit C
778ec4e commit B
cfe4665 commit A
432cb61 rebaseTestrebaseするコミットを指定する
git rebase -i コミットid
git rebase -i HEAD~4指定するコミットidは、リベースしたいところの一つ前を指定すること。 上記の例だと、 以下の3つのコミットをまとめたい場合は、1つ前のコミット 432cb61 rebaseTest を指定する。 (HEAD指定だと HEAD~4 )
-
commit A
-
commit B
-
commit C
pick cfe4665 commit A
pick 778ec4e commit B
pick 426f407 commit C
# Rebase ccaab03..426f407 onto ccaab03 (4 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message指示コマンド
-
(p)pick コミットをそのまま残す。
-
(r)reword コミットメッセージを変更。
-
(e)edit コミット自体の内容を編集。
-
(s)squash 直前のpickを指定したコミットに統合。メッセージも統合。
-
(f)fixup 直前のpickを指定したコミットに統合。メッセージは破棄。
pick cfe4665 commit A
s 778ec4e commit B
s 426f407 commit C
# Rebase ccaab03..426f407 onto ccaab03 (4 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message# This is a combination of 3 commits.
ここに新しいコミットメッセージを書く
# This is the 1st commit message:
commit A
# This is the commit message #2:
commit B
commit CcommitA commitB commitCがrebaseされた。
8c44d3b (HEAD -> develop) new message
432cb61 rebaseTestReactでApolloClientを使ってuseQueryしてみる基本
ReactでApolloを使うキャッチアップのため、GithubのGraphQLAPIを使ってクエリを叩いてみた。 graphql-code-generatarもテストしてみたので使用感について書いてみる。
環境構築
環境構築はCRAで。
npx create-react-app graphql-react-app --template typescript
ApolloClientとGraphQLをインストールします。
yarn add @apollo/client graphql
今回は、簡単にユーザー情報を取得して表示させてみたいと思います。GitHub GraphQL Explorerでqueryをテストし、これをそのまま使用します。
ApolloProviderの読み込み
まずは、ReactアプリでApolloClientを使用するため、ApolloProviderを読み込ませます。
index.tsx
import React from 'react'
import ReactDOM from 'react-dom'
import { ApolloProvider, ApolloClient, InMemoryCache } from '@apollo/client'
const token = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
const client = new ApolloClient({
uri: '<https://api.github.com/graphql>',
headers: { authorization: `Bearer ${token}` },
cache: new InMemoryCache(),
})
ReactDOM.render(
<ApolloProvider client={client}>
<React.StrictMode>
<App />
</React.StrictMode>
</ApolloProvider>,
document.getElementById('root'),
)
githubのGraphQLAPIを使用するにはtokenが必要なので、headersに渡しています。通常、環境変数に入れるのですがここではベタ書きしています。
ComponentでuseQueryする
User.tsx
import React from 'react'
import { useQuery, gql } from '@apollo/client'
import Styled from 'styled-components'
export type User = {
user: {
name: string
url: string
location: string
avatarUrl: string
createdAt: string
}
}
const USER = gql`
query ($userName: String!) {
user(login: $userName) {
name
url
location
avatarUrl
createdAt
}
}
`
type ContainerProps = {
className?: string
}
type Props = {
data: User | undefined
} & ContainerProps
export const Component: React.VFC<Props> = ({ className, data }) => (
<div className={className}>
<div className="User__box">
<img
className="User__avatar"
src={data?.user.avatarUrl}
alt={data?.user.name}
/>
<p className="User__name">{data?.user.name}</p>
<p className="User__location">{data?.user.location}</p>
<p className="User__createdAt">{data?.user.createdAt}</p>
</div>
</div>
)
export const StyledComponent = Styled(Component)`
// css
`
export const ContainerComponent: React.VFC<ContainerProps> = (
containerProps,
) => {
const userName = 'KoheiKojima'
const { data, loading, error } = useQuery<User>(USER, {
variables: { userName },
})
const props = { data }
if (loading) return <>Loading</>
if (error) return <>{error}</>
return <StyledComponent {...containerProps} {...props} />
}
export default ContainerComponent
はい、これでApolloClientを通してGitHubのGraphQLAPIからUserデータをフェッチすることができました。
一つずつ簡単に解説していきます。
const USER = gql`
query ($userName: String!) {
user(login: $userName) {
name
url
location
avatarUrl
createdAt
}
}
`
GitHub GraphQL Explorerでテストしたクエリを記述
gql関数でクエリ文字列をラップして、記述していきます。ここでは、userNameはベタ書きせず、引数で受け取る形式にしています。
次に、useQueryHookを使って上記のクエリを実行します。これは、Componentのマウント時に実行されます。
const userName = 'KoheiKojima'
const { data, loading, error } = useQuery<User>(USER, {
variables: { userName },
})
const props = { data }
if (loading) return <>Loading</>
if (error) return <>{error}</>
値としてはloading、error、dataが返ってきます。
Apolloクライアントは、サーバーからクエリ結果をフェッチするたびに、そのフェッチ結果をローカルに自動的にキャッシュしてくれるみたいです。 それによって、同じクエリの実行が非常に高速になるそうな。
GraphQL Code Generatorで自動的に型生成する
GraphQLのスキーマからTypeScriptの型を自動生成してくれるライブラリで、複雑になりがちな型宣言を楽ちんにしてくれる便利なツール。
基本は、公式の手順どおり進めていけば問題なかったです。
パッケージインストールする
yarn add -D @graphql-codegen/cli @graphql-codegen/typescript @graphql-codegen/typescript-react-apollo @graphql-codegen/typescript-operationscodegen.ymlの作成
yarn graphql-codegen init質問項目は一旦すべてエンターで進め、最後のscriptコマンドは任意のコマンドを入れてください。(genarateなど)
今回は、以下のように書き換えました。
overwrite: true
schema: 'schema.graphql'
generates:
src/graphql/generate/index.ts:
documents: 'src/graphql/documents.ts'
plugins:
- 'typescript'
- 'typescript-operations'
- 'typescript-react-apollo'
src/graphql/documents.tsを参照 schema.graphqlのスキーマをTypescirptの型でsrc/graphql/generate/index.tsに自動で生成する
schema.graphqlの作成
スキーマの記述をしていきます。 ここでは、GitHub GraphQL Explorerの型定義をほぼそのまま記述。
type User {
name: String!
url: String!
location: String!
avatarUrl: String!
createdAt: String!
}
type Query {
user(login: String!): User!
}documents.tsの作成
src/graphql/documents.tsでは、実行したいクエリを記述します。
import { gql } from '@apollo/client'
gql`
query User($userName: String!) {
user(login: $userName) {
name
url
location
avatarUrl
createdAt
}
}
`Componentで読み込み
yarn generateして成功すれば、型定義ファイルが作成されます。
yarn generate
yarn run v1.22.10
$ graphql-codegen --config codegen.yml
✔ Parse configuration
✔ Generate outputs
✨ Done in 3.21s.
今回作成された型定義ファイル
import { gql } from '@apollo/client';
import * as Apollo from '@apollo/client';
export type Maybe<T> = T | null;
export type Exact<T extends { [key: string]: unknown }> = { [K in keyof T]: T[K] };
export type MakeOptional<T, K extends keyof T> = Omit<T, K> & { [SubKey in K]?: Maybe<T[SubKey]> };
export type MakeMaybe<T, K extends keyof T> = Omit<T, K> & { [SubKey in K]: Maybe<T[SubKey]> };
const defaultOptions = {}
/** All built-in and custom scalars, mapped to their actual values */
export type Scalars = {
ID: string;
String: string;
Boolean: boolean;
Int: number;
Float: number;
};
export type Query = {
__typename?: 'Query';
user: User;
};
export type QueryUserArgs = {
login: Scalars['String'];
};
export type User = {
__typename?: 'User';
avatarUrl: Scalars['String'];
createdAt: Scalars['String'];
location: Scalars['String'];
name: Scalars['String'];
url: Scalars['String'];
};
export type UserQueryVariables = Exact<{
userName: Scalars['String'];
}>;
export type UserQuery = { __typename?: 'Query', user: { __typename?: 'User', name: string, url: string, location: string, avatarUrl: string, createdAt: string } };
export const UserDocument = gql`
query User($userName: String!) {
user(login: $userName) {
name
url
location
avatarUrl
createdAt
}
}
`;
/**
* __useUserQuery__
*
* To run a query within a React component, call `useUserQuery` and pass it any options that fit your needs.
* When your component renders, `useUserQuery` returns an object from Apollo Client that contains loading, error, and data properties
* you can use to render your UI.
*
* @param baseOptions options that will be passed into the query, supported options are listed on: <https://www.apollographql.com/docs/react/api/react-hooks/#options>;
*
* @example
* const { data, loading, error } = useUserQuery({
* variables: {
* userName: // value for 'userName'
* },
* });
*/
export function useUserQuery(baseOptions: Apollo.QueryHookOptions<UserQuery, UserQueryVariables>) {
const options = {...defaultOptions, ...baseOptions}
return Apollo.useQuery<UserQuery, UserQueryVariables>(UserDocument, options);
}
export function useUserLazyQuery(baseOptions?: Apollo.LazyQueryHookOptions<UserQuery, UserQueryVariables>) {
const options = {...defaultOptions, ...baseOptions}
return Apollo.useLazyQuery<UserQuery, UserQueryVariables>(UserDocument, options);
}
export type UserQueryHookResult = ReturnType<typeof useUserQuery>;
export type UserLazyQueryHookResult = ReturnType<typeof useUserLazyQuery>;
export type UserQueryResult = Apollo.QueryResult<UserQuery, UserQueryVariables>;UserTypeなどに加えて、useUserQueryHookとイベントに発火させて実行させるuseUserLazyQueryHookも自動作成されています。これをそのままComponentで読み込ませれば、型補完がされるようになります。
const { data, loading, error } = useUserQuery({
variables: {
userName,
},
})スキーマファイルを読み込ませれば、自動で型を作成してくれるのは良い。フロントエンド側で投げたクエリに対して、型補完が効くのはかなり利便性が高そうな印象を受けた。特に、Hooksも自動作成してくれるのはありがたい。
クエリの量が増えてきた時、自動作成がどこまで柔軟に対応できるのかが、微妙なところ。個人的にはコツコツ型定義してファイル分割して管理したほうが後々管理しやすいんじゃないかな?と感じた。 ただ、一度に型定義やHookを作成してくれるのは便利すぎる。
emotionで:first-child がエラーになる
今回はGatsbyで起こったが、emotionの仕様みたいなのでメモしておく。
"@emotion/react": "^11.4.1",
"@emotion/styled": "^11.3.0",
やりたいこと
こんな感じで first-childに対してスタイルを当てたかった。
`.Pagination__block {
&:first-child.-active {
margin-right: 8px;
& ~ .-nextNext {
display: block;
}
}
}
emotionでCSSを書いてビルドするとコンソールエラーが出るのを確認した。
エラー内容
The pseudo class ":first-child" is potentially unsafe when doing server-side rendering. Try changing it to ":first-of-type".
疑似クラスの「:first-child」は、サーバーサイドレンダリングを行う際に安全でない可能性があります。:first-of-typeに変更してみてください。
「なんで???」
「emotion first-child」でググる
emotion-js に issueがあった!
The docs have taken a sharp downhill turn with v10 #1059
@jhoffmcd SSRは、コンポーネントの一部としてスタイル要素をレンダリングします(したがって、SSRを実行すると、多くのスタイル要素が作成されますが、それはパフォーマンスの問題ではありません)。そうすることで、SSRのみが機能します。最初の子はスタイルタグであるため、この疑似セレクターは「安全ではありません」という警告があります。全員がSSRを実行しているわけではないため、少なくともこの警告をオフにするとよいことに同意します。
Problems surrounding SSR injection of style and unreliability of :first-child selectors #1178
エモーションv10 +では、スタイル付きコンポーネントまたはcss prop値で、、、またはセレクターを使用する:first-childと:nth-child、新しい警告がスローされ:nth-last-childます。これは、SSRを使用する場合、style要素が関連するコンポーネントのすぐ上(先頭に追加)に注入されるためです。
issueのコメントを見る限り、Style要素がコンポーネントの先頭に差し込まれる形でレンダリングされるらしい。
なので、 first-child を指定してしまうと、 「style のことを指してるの?」となり、エラーが出てくる。
styleがコンポーネントの先頭に追加されるってどういうこと?
yarn build してみて、htmlファイルを生成してみる。
<div id="___gatsby">
<div style="outline:none" tabindex="-1" id="gatsby-focus-wrapper">
<style data-emotion="css 1j6r3sl">.css-1j6r3sl .postList{max-width:1000px;margin:0 auto;padding:60px 40px;}@media (max-width: 767px){.css-1j6r3sl .postList{padding:40px 16px;}}</style>
<style data-emotion="css-global sjlswe">*:where(:not(iframe, canvas, img, svg, video):not(svg *)){all:unset;display:revert;}*,*::before,*::after{box-sizing:border-box;}ol,ul{list-style:none;}img{max-width:100%;}table{border-collapse:collapse;}html{font-size:62.5%;}body{font-family:sans-serif;color:#333;}@media (prefers-color-scheme: dark){body{background-color:#212122;color:#fefefe;}}*{box-sizing:border-box;-webkit-font-smoothing:antialiased;-moz-osx-font-smoothing:grayscale;font-weight:400;line-height:1.6em;letter-spacing:0;}img{display:block;width:100%;}a{display:block;}sup{font-size:80%;line-height:1em;color:inherit;font-weight:inherit;}pre{display:block;width:100%;white-space:pre-wrap;}pre[class*='language-']{background-color:#1c1b1b;display:block;margin:0 0 20px;padding-right:1rem;padding-left:2rem;border-radius:0 4px 4px 4px;}code[class*='language-'],pre[class*='language-']{color:#fff;}:not(pre)>code[class*='language-text']{padding:2px 10px 3px 12px;margin:0;color:#f14668;text-shadow:none;background-color:whitesmoke;}.gatsby-highlight-code-line{background:#545454;display:block;}.gatsby-code-title{background:#2e96b5;color:#eee;padding:6px 12px;font-size:0.8em;line-height:1;font-weight:bold;display:table;border-radius:4px 4px 0 0;}</style>
<div class="css-1j6r3sl es84g1o0 -Top">
<style data-emotion="css yl514p">.css-yl514p .BaseTemplate__container{padding:0 16px;}</style>
<div class="BaseTemplate css-yl514p e2u8ox10 -Top">
<style data-emotion="css 17zshvp">.css-17zshvp{padding:8px 16px;text-align:center;box-shadow:0 0 1em rgba(0, 0, 0, 0.1);}.css-17zshvp .Header__inner{max-width:960px;margin:0 auto;padding:0 16px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-box-pack:justify;-webkit-justify-content:space-between;justify-content:space-between;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}.css-17zshvp .Header__logo{font-size:18px;font-weight:bold;cursor:pointer;}.css-17zshvp .Header__navMenu{display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;}.css-17zshvp .Header__navMenu li{margin:0 8px;}.css-17zshvp .Header__navLink{font-size:16px;cursor:pointer;}</style>
<div class="Header css-17zshvp e1nmgjw0">
<header>
<div class="Header__inner">
<a aria-current="page" class="Header__logo" href="/">Blog</a>
<nav class="Header__nav">
</nav>
</div>
</header>
</div>
<main class="BaseTemplate__container">
<ul class="postList">
<style data-emotion="css 2eh5bq">.css-2eh5bq .PostList__box{padding:16px;border:1px solid #eee;cursor:pointer;-webkit-transition:box-shadow 0.4s ease;transition:box-shadow 0.4s ease;}.css-2eh5bq .PostList__box:not(:last-child){margin-bottom:20px;}.css-2eh5bq .PostList__box:hover{box-shadow:0 0 1em rgba(0, 0, 0, 0.1);}.css-2eh5bq .PostList__title{font-size:24px;font-weight:bold;margin-bottom:0.5em;}.css-2eh5bq .PostList__date{font-size:14px;}@media (prefers-color-scheme: dark){.css-2eh5bq .PostList__box{border:1px solid #545454;}.css-2eh5bq .PostList__box:hover{box-shadow:0 0 1em rgba(255, 255, 255, 0.2);}}</style>
<div class="PostList css-2eh5bq e1rod1k60">
</div>
</ul>
</main>
<style data-emotion="css 1pqwhda">.css-1pqwhda{width:100%;padding:16px;text-align:center;}.css-1pqwhda .Footer__copyright{font-size:14px;}</style>
<div class="Footer css-1pqwhda eadoj9z0"><small class="Footer__copyright">© Kohei Kojima</small></div>
</div>
</div>
</div>
</div>確かに、buildされたhtmlファイルを見ると、コンポーネントの前(先頭)にstyleが追加されている。
これを見越して、エラーを出してくれていたのかー。
解決方法
The pseudo class ":first-child" is potentially unsafe when doing server-side rendering. Try changing it to ":first-of-type".
このメッセージ通り、first-of-type に置き換えるのよさそう
まとめ
-
emotionでは
first-childではなくfirst-of-typeを使う -
<style>タグが差し込まれることを見越したCSSスタイリングを行う
GatsbyでuseContextを使う際はgatsby-browserに定義する
GatsbyでuseContextを使ってダークモード対応をした(このブログではない)のですが、useContextのstateの挙動がうまく動かず、見事にハマったのでメモしておきます。
結論から言うと、「公式ドキュメントちゃんと読もう」です。
useContextで発生した問題
こちらの記事を参考に、ダークモードの実装を進めていました(めっちゃ参考になる!) The Quest for the Perfect Dark Mode
Gatsbyの記事ではなく、Reactでダークモード対応する方法だったのですが、Gatsbyもstate使えるし、問題ないだろう。ってことで、そのまま実装。ダークモードの切り替え、localStorageへの保存はうまく行ったのですが、stateの動きがおかしいことに気づきました。
ダークモード切り替え直後に画面遷移すると、dark⇔lightが切り替わってしまう。
-
TOPページ 初回レンダリング時(
dark) -
TOPページで
lightへ切り替え -
検索ページへ遷移
-
darkに戻る このときlocalStorageはlightAppStateはdark
localStorageには保存されているのに、useContextのstateがリセット(というかtoggle)になる謎現象。 Providerがうまく動いてないっぽい?
当時の構成は、/components/templates/Layout/index.tsxにProviderを読み込ませてchildrenをラップする形でした。
公式ドキュメントを見る
ちゃんと読めば書いてました。
Using React Context API with Gatsby | Modifying the Gatsby Browser file
Next, write the following code within the gatsby-browser.js file, which is in the root folder in a Gatsby project:
gatsby-browser.js
import React from "react"
import { ThemeProvider } from "./src/context/ThemeContext"
export const wrapRootElement = ({ element }) => (
<ThemeProvider>{element}</ThemeProvider>
)The ThemeProvider component exported from the ThemeContext.js file wraps the root element and is exported as wrapRootElement. This API is then invoked appropriately by the Gatsby API runner.
gatsby-browser.jsにProviderをexportすることでルート要素をラップしてexportされます。 これにより、GatsbyAPIが正常に動作させることができるということ。
まとめ
-
GatsbyでuseContextを使うときは、GatsbyBrowserAPIを介してルート要素をプロバイダーでラップする
-
公式ドキュメントよむ
ReactComponentのベストプラクティス
結論は、「Presentialも、Containerも、StyledComponentも全部まとめて書きたい!」です。
Reactでコンポーネントを書くときに、PresentialとContainerの役割を分離するというのが基本みたい。 ファイルそのものを分割してそれぞれに役割を持たせるというのがスタンダード。
ただ、CSS-inJSでスタイルも同じファイルに定義できるようになった今、ファイルを分割しすぎるのもちょっと扱いにくい。 ロジックとビューに改修を入れたい場合、複数のファイルを見に行く必要があり、面倒に感じてしまう。。
そこで参考にさせていただいたのがこちらの記事
DOM,Style,Containerで分離させる
// (1) import層
import React from 'react'
import styled from 'styled-components'
// (2) Types層
type ContainerProps = {...}
type Props = {...} & ContainerProps
// (3) DOM層
const Component: React.FC<Props> = props => (...)
// (4) Style層
const StyledComponent = styled(Component)`...`
// (5) Container層
const Container: React.FC<ContainerProps> = props => {
return <StyledComponent {...props} />
}
1つのファイルで技術を分離させて、それぞれの役割をさせているといった感じ。
DOM層はpropsを受け取ってDOMに反映するだけ。ロジックを持たず、ステートレス(状態を持たない)レイヤー。 まだやったことはないが、constで定義されているので、コンポーネントだけを抜き出してテストすることが簡単にできる。
Style層はDOMComponentを読み込んでStyledComponentを適用させる。個人的にはクラス名をつけてBEMの記述をするのがベストだと思っている。
理由は、> tagのようにComponentのchildren以外へのスタイル適用を防いだりする必要がないし、CSSModuleへの移行も簡単にできるから。
ContainerComponentは、明確にビジネスロジックが入る。useEffectだったり、stateの操作を行うステートフルな部分。
1ファイルにまとまっていてかつそれぞれの役割が明確に分離されているのが個人的には理解しやすかった。
上記参考にしたComponent例
import React from "react";
import styled from "styled-components";
/*
Component名を定数で定義
Component名がBEMのBlock要素としてクラス名を定義するため。
外部ComponentにComponentスタイルの影響を与えないため
*/
const COMPONENT_NAME = "User";
/*
ContainerのPropsを定義
親Componentから渡されたpropsはContainerで読み込まれるため、こちらで定義する。
GatsbyのGraphQLもこちらで。
*/
type ContainerProps = {
user: {
name: string;
age: number;
};
};
/*
ContainerからDOMComponentへ渡すprops
*/
type Props = {
hello: string;
handleClick: (name: string) => void;
} & ContainerProps;
/*
DOMComponent
*/
const Component: React.VFC<Props> = (props) => (
<div className={`${COMPONENT_NAME}__container`}>
<p className={`${COMPONENT_NAME}__name`}>{props.user.name}</p>
<p className={`${COMPONENT_NAME}__age`}>{props.user.age}</p>
<button onClick={() => props.handleClick(props.user.name)}>Click!</button>
<p className={`${COMPONENT_NAME}__sayHello`}>{props.hello}</p>
</div>
);
/*
StyledComponent
Component名をBlock要素として、BEMで記述する
*/
const StyledComponent = styled(Component)`
.User__name {
padding: 8px;
font-size: 16px;
font-weight: bold;
}
`;
/*
ContainerComponent
受け取ったpropsをDOMComponentへ渡す
あるいは、ロジックを加えたものを渡す
state、useEffect等のすべてのロジックはここに記述
*/
const Container: React.FC<ContainerProps> = (props) => {
const [hello, setHello] = React.useState("");
const handleClick = React.useCallback(
(name: string) => {
setHello(`Hello! ${name}!!`);
},
[setHello]
);
return <StyledComponent {...props} handleClick={handleClick} hello={hello} />;
};
/*
ContainerComponentをdefault exportする。
Containerが無いComponentの場合は、
export default StyledComponent; になる
*/
export default Container;
ディレクトリ構造とファイル名
仕事ではAtomicDesignを使用している。
コードが長くなったり、見にくいなーと感じたら、Componentに切り分けたりすることもあるのですが、コードレビューを受けると、「使い回さない部分はComponentに分ける意味ないですよね」みたいな意見があった。
AtomicDesign に倣うこともありますが、いきなりそれに沿った構成にすることはありません。「特定の箇所を変更したい場合、誰でも想像したとおりの場所にある」という感覚を特に大事にしています。たとえば、要素リストを含む Component は次の様な構成にします。この様な単純な名称であれば、どこを修正すれば良いのか一目瞭然です。 経年劣化に耐える ReactComponent の書き方
Users
├── index.tsx
├── title.tsx
└── list
├── index.tsx
├── title.tsx
└── item
├── index.tsx
├── title.tsx
├── avatar.tsx
└── icon.svg
確かに、この構成だとめっちゃわかりやすい。 それぞれのindex.tsxがエントリーポイントになっていて、同階層のComponentを読み込んでいるイメージだと思う。
また、必要なファイルがディレクトリにまとまっているので、 AtomicDesignのように/moleculesと/organismsと/atomsと行ったり来たりしなくていいのがいい!
AtomicDesign に倣う場面は、これが複数のComponentで利用される様になったタイミングです。はじめからそれに倣うと、オーバーエンジニアリングになるため、複数のComponentで利用されるタイミングで、共有Component ディレクトリへと移します(リファクタ)。限定的コンテキストに閉じられた Component であるならば、はじめから AtomicDesign のルールに則ることが却って足枷になると感じています。 経年劣化に耐える ReactComponent の書き方
いきなりAtomicDesignにしないのがポイントかも。プロジェクトの進捗によって、Componentが必要とされるタイミングでAtomicDesignへ落とし込む(リファクタリング)
AtomicDesignを採用していて、共通化できてないComponentって、どうやって管理しているんだろうか?templatesとかでまとめてるのか。 上記の例みたいに、ディレクトリを切った構成にするのもありかなと思った。
参考リンク
ReactComponentのベストプラクティスを考えてみた
Gatsby+TypeScript+ESLint+Prettier+StyleLintのブログ構築
Gatsbyブログを作ったので、雑に環境構築についてメモしておく。 TypeScriptやReactのキャッチアップも兼ねていたので、ESLintやPrettier、StyleLintも入れてみた。
前回のブログでも書いたが、React+TypeScriptキャッチアップにはもってこいだと思っているので、駆け出しフロントエンドエンジニアの方はぜひ挑戦してほしい。
導入手順
-
Gatsbyのセットアップ
-
TypeScriptのインストール
-
ESLintの設定
-
Prettierの設定
-
ESLintとStyleLint設定
-
StyleLintの設定
-
もろもろの設定
Gatsbyのセットアップ
$ npm init gatsby
What would you like to call your site?
✔ · myblog
What would you like to name the folder where your site will be created?
✔ user/ blog
? Will you be using a CMS?
(Single choice) Arrow keys to move, enter to confirm
✔ No (or I'll add it later)
–
WordPress
Contentful
Sanity
DatoCMS
Shopify
Netlify CMS
? Would you like to install a styling system?
(Single choice) Arrow keys to move, enter to confirm
No (or I'll add it later)
–
Sass
styled-components
✔ Emotion
PostCSS
Theme UI
? Would you like to install additional features with other plugins?
(Multiple choice) Use arrow keys to move, enter to select, and choose "Done" to confirm your choices
◯ Build and host for free on Gatsby Cloud
❯◉ Add responsive images
◉ Add the Google Analytics tracking script
◉ Add page meta tags with React Helmet
◉ Add an automatic sitemap
◉ Generate a manifest file
◉ Add Markdown support (without MDX)
◉ Add Markdown and MDX support
今回はCMSは使用せずMarkdownベタ書きします。 CSSフレームワークはemotionを選択しました。
npm run develop
TypeScriptのインストール
GatsbyにはTypeScriptが統合されていて、すでに使用できる状態です。 型チェックをするためにはTypeScriptをインストールする必要があります。
GatsbyでTypeScriptを拡張するためのプラグイン gatsby-plugin-typescript もインストールする
$ yarn add -D typescript gatsby-plugin-typescript
ESLintの設定
$ yarn add -D eslint eslint-loader
eslint --initして設定ファイルを作成する
$ yarn run eslint --init
? How would you like to use ESLint? (Use arrow keys)
To check syntax only
> To check syntax and find problems
To check syntax, find problems, and enforce code style
? What type of modules does your project use? (Use arrow keys)
> JavaScript modules (import/export)
CommonJS (require/exports)
None of these
? Which framework does your project use? (Use arrow keys)
> React
Vue.js
None of these
? Does your project use TypeScript? (y/N) y
? Where does your code run? (Press <space> to select, <a> to toggle all, <i> to invert selection)
>(*) Browser
( ) Node
? What format do you want your config file to be in?
JavaScript
YAML
> JSON
The config that you've selected requires the following dependencies:
eslint-plugin-react@latest @typescript-eslint/eslint-plugin@latest @typescript-eslint/parser@latest
? Would you like to install them now with npm? (Y/n) y
.eslintrc.json
{
"env": {
"browser": true,
"es6": true
},
"extends": [
"eslint:recommended",
"plugin:react/recommended",
"plugin:@typescript-eslint/eslint-recommended"
],
"globals": {
"Atomics": "readonly",
"SharedArrayBuffer": "readonly"
},
"parser": "@typescript-eslint/parser",
"parserOptions": {
"ecmaFeatures": {
"jsx": true
},
"ecmaVersion": 2018,
"sourceType": "module"
},
"plugins": [
"react",
"@typescript-eslint"
],
"rules": {
}
}
ESLintのルールセット・プラグインの導入
eslint-config-airbnb とその依存関係をインストール
$ yarn add -D eslint-config-airbnb eslint-plugin-import eslint-plugin-jsx-a11y eslint-plugin-react eslint-plugin-react-hooks
typescript-eslint をインストール
$ yarn add -D @typescript-eslint/eslint-plugin @typescript-eslint/parser
gatsby-plugin-eslint のインストール
$ yarn add -D gatsby-plugin-eslint
上記全部まとめてインストール
yarn add -D eslint-config-airbnb eslint-plugin-import eslint-plugin-jsx-a11y eslint-plugin-react eslint-plugin-react-hooks @typescript-eslint/eslint-plugin @typescript-eslint/parser gatsby-plugin-eslint
gatsby-config.js にeslintの設定を追加
plugins: [
/*
...省略
*/
{
resolve: 'gatsby-plugin-eslint',
options: {
// Gatsby required rules directory
// Default settings that may be ommitted or customized
stages: ['develop'],
extensions: ['js', 'jsx', 'ts', 'tsx'],
exclude: ['node_modules', 'bower_components', '.cache', 'public'],
// Any additional eslint-webpack-plugin options below
// ...
},
},
]
}
Prettierの設定
$ yarn add -D prettier
.prettier.json
{
"singleQuote": true,
"trailingComma": "all",
"semi": false
}
.prettierignore の編集
.cache/
build/
public/
**/coverage/
**/node_modules/
node_modules/
node_modules
**/*.min.js
*.config.js
.*lintrc.js
ESLintとPrettierの競合を解決
$ yarn add -D eslint-config-prettier
.eslintrc.json
{
/*
...省略
*/
"extends": [
"airbnb",
"eslint:recommended",
"plugin:@typescript-eslint/eslint-recommended",
"plugin:@typescript-eslint/recommended",
"plugin:react/recommended",
"plugin:@typescript-eslint/recommended-requiring-type-checking",
"prettier",
"prettier/@typescript-eslint",
"prettier/react
],
"parser": "@typescript-eslint/parser",
"settings": {
"import/resolver": {
"node": {
"extensions": [
".js",
".jsx",
".ts",
".tsx"
]
}
}
},
/*
...省略
*/
"rules": {
"no-use-before-define": "off",
"quotes": [2, "single", { "avoidEscape": true }],
"react/jsx-filename-extension": [
"error",
{ "extensions": [".jsx", ".tsx"] }
],
"react/prop-types": "off",
"@typescript-eslint/explicit-module-boundary-types": "off",
"@typescript-eslint/no-var-requires": "off",
"react/no-danger": "off",
"react/no-unescaped-entities": "off",
"import/no-extraneous-dependencies": "off",
"import/extensions": [
"error",
"ignorePackages",
{
"js": "never",
"jsx": "never",
"ts": "never",
"tsx": "never"
}
]
}
}
package.json
"scripts": {
"develop": "gatsby develop",
"start": "gatsby develop",
"build": "gatsby build",
"serve": "gatsby serve",
"clean": "gatsby clean",
"format:prettier": "prettier --write \\\\"**/*.{js,jsx,ts,tsx,json,md}\\\\"",
"format:eslint": "eslint --fix \\\\"**/*.{js,jsx,ts,tsx}\\\\"",
"format": "yarn format:eslint && yarn format:prettier"
},
参考サイト
StyleLintの設定
どうやら、emotionはstylelintにまだ対応していないっぽい。 ただ、 styled-component と同様の設定でも動くらしいので使ってみる。
ただし、FIXオプションは使えないので自動フォーマットは使えない。IDEでのエラーチェックのみ。
Gatsbyにはstyled-componentsのプラグインをいれる
$ yarn add -D gatsby-plugin-styled-components
gatsby-config.js
plugins:
`gatsby-plugin-styled-components`,
.stylelintrc.json
{
"processors": ["stylelint-processor-styled-components"],
"extends": [
"stylelint-config-standard",
"stylelint-config-styled-components",
"stylelint-prettier/recommended"
],
"rules": {
"string-quotes": "single"
}
}
package.json
"scripts: {
...
"stylelint": "stylelint \\\\"**/*.ts\\\\""
}
一応エラーチェックはしてくれた。 ただ、前述したようにFIXオプションは動かないっぽい
参考サイト GatsbyをTypeScript化し、コードの検証と整形をする(ESLint、Prettier、stylelint + styled-components)
もろもろの設定 (参考リンク)
ローカル環境をスマホ実機で確認する
package.json
"develop": "gatsby develop -H 0.0.0.0",
GatsbyJS×TypeScriptでブログを作ってみた
Gatsby.jsでブログを構築してみた。
Gatsby.jsとは?
React製の静的サイトジェネレーターです。webサイトを作る時に使います。 Gatsby.jsは公式サイトに「blazing fast🔥」と自分で書いちゃうほど早いフレームワーク
-
Gatsbyによって生成されるWebサイトはSPAとして出力される
-
様々な最適化・コード分割をGatsbyがやってくれる
-
GatsbyのサイトはSPA、初回ロード以降はロード時間ゼロで画面遷移できる
-
Gatsbyが専用のLinkコンポーネントを用意しており、それを用いると、ページ内に入っているリンクを自動で検出してプリフェッチを行ってくれる。(必要そうなデータは自動で読み込んでくれる)
-
SSRと同様、配信されるのはHTML/CSS & JavaScriptなので、クライアントサイドでDOMを構築する時間も不要となり、JavaScriptの実行時間を短縮できる
-
Wordpressのように動的にページを作成することも無くなり、サーバサイドのプログラム実行時間とクライアントサイドのプログラム実行時間を両方削減することが出来る
今回、ブログを作ってみて、「簡単なサイトなら全部Gatsbyでいいんじゃね?」と思うほど使いやすかった。
技術スタック
-
Gatsby 3.13.0
-
TypeScript 4.4.2
-
emotion 11.3.0
-
eslint 7.32.0
-
prettier 2.3.2
-
stylelint 13.13.1
GatsbyJSにはネイティブでTypeScriptをサポートしているので、特に設定なしでTypeScriptが使用できる。 が、タイプチェックを行うためにはTypeScriptのインストールと .tsconfig ファイルの作成が必要。
今回は、React、TypeScript、GraphQLのキャッチアップも兼ねているのでこういった構成にしてみた。 個人ブログには不要な感じもするが、より実務感を出すためにも、リンターの設定を入れてある。
markdownのテスト
コードハイライトが反映されているかのテスト
const hoge = 'hogehoge'
<div>hoge</div>
React、TypeScriptのキャッチアップに最適
個人的には、React、TypeScriptのキャッチアップに最適だと感じた。 公式のチュートリアルや技術書でインプットを終えた後、GatsbyでTypeScriptの環境を構築してコンポーネントの開発を進めたほうが理解が早い。
emotionやstyled-componentsを入れて、themeの設計だったり、やれることはたくさんある。 ついでにGraphQLも学べるので、一石三鳥だ。
何より、個人で使うブログを自分好みにカスタマイズしながら開発するほうが楽しいし数倍捗る。
駆け出しフロントエンドエンジニアには是非おすすめしたい。
表面的な事実だけで判断せず、背景や理由を推し量るWhy型思考
「なぜ」を突き詰めれば本質が見えてくる

物事の表面だけ見てない?
What → 目に見える形になったもの。情報や知識、具体的な行動
Why → 形の背景、理由、目的
物事の表面だけを見るか、物事の背景も含めてみるかの違いがある。
たとえば
今ある規則やルールは、作られた背景や目的がある。
作られた当時と違う状況になったとしたら、新しいものを作り直すことが必要になる。
What型思考の人は、過去の事例や成功体験をそのまま踏襲してしまう事が多い。
- どんな背景、目的があったのか
- それは現在の状況でも使えるものなのか
Whyの部分にも目を向け、使えない部分は積極的に変えていく。
ビジネスでの依頼者と解決者の関係
依頼者「○○を出してほしいんだけど」
解決者「わかりましたー!」
言われたことをそのままうけとって、即座に次のアクションに移っています。
これだと、使用目的がわかりません。
依頼者「○○を出してほしいんだけど」
解決者「○○でどんなことをするのでしょうか?」
依頼者「実は✗✗をやりたくて、○○のデータを使えないかと思って」
解決者「それなら△△がありますよ」
依頼者から言われた(What)を、「なぜ?」の一言で押し返す。
そこから抽出されたニーズや目的(Why)を解釈して、最適なWhatを提案し直す。
上司からの指示って、大体はWhatのみで降りてくる事が多く、その背景や目的の説明がされない場合がほとんど。
大抵の人はそのまま受け取って処理してしまいがちですよね。
なぜ?から思考がスタートする
なぜ?はその裏側を探りたいという意図で、物事の本質に迫っていく質問。
重要なのは、なぜ?を繰り返し問うこと。
「なぜですか?」と聞くと、毛嫌いされるケースが多いが、本質を見抜く訓練は必須だと思っている。
- 物事を疑ってかかる
- 他人と同じことをしない
- 性格悪くなれ!
- 考える孤独に耐えよ
Why型思考人間って、めっちゃ孤独やん。
確かに、人と会話していて「なぜ?」「その背景は?」みたいに聞かれたら、、会話したくなくなります。普段の会話でそこまで考えてないって。
ビジネス上で本質を考える場合には、どんどん使うべき思考法だとは思いますが、人とのコミュニケーションでは用法用量に注意ですね。
「Why型思考」が仕事を変える 鋭いアウトプットを出せる人の「頭の使い方」 (PHPビジネス新書)
【スクレイピング】ナンバーズの当選番号を直近まで全件取得
今回もスクレイピングしていきます。
pythonを使ってのスクレイビング開発の依頼・外注 | Webシステム開発・プログラミングの仕事・副業 【クラウドソーシング ランサーズ】[ID:3468971]
mizuho銀行の宝くじ"ナンバーズ3"の1回目~直近の回の全データを取得したいです。 取得していただきたいデーターは↓ 「 '回別'(第1回) '当選日'(1994年10月7日) '抽選数字'(191) 」
ライブラリインポート
from bs4 import BeautifulSoup import requests import pandas as pd from time import sleep from selenium import webdriver from selenium.webdriver.chrome.options import Options url = 'https://www.mizuhobank.co.jp/retail/takarakuji/check/numbers/numbers3/index.html?year=2021&month=5' op = Options() op.add_argument("--headless"); op.add_argument('--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36') op.add_argument('--lang=ja-JP')
直近の当選番号をデータフレームに格納

ナンバーズの当選番号はA表とB表に分かれているので、それぞれから収集していきます。
まずはA表から。
# (A表)先月から過去1年間の当せん番号 のリンクを格納した配列を返す def backnumber_latest_link_to_lists(): url = 'https://www.mizuhobank.co.jp/retail/takarakuji/check/numbers/backnumber/index.html' driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=op) driver.get(url) res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') lists = [] links = driver.find_elements_by_partial_link_text('ナンバーズ3') for link in links: lists.append(link.get_attribute('href')) return lists backnumber_latest = backnumber_latest_link_to_lists() # A表から回別、抽選日、抽選数字をDataFrameに変換 backnumbers = [] for link in backnumber_latest: url = link driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=op) driver.get(url) no = driver.find_elements_by_class_name('bgf7f7f7') date = driver.find_elements_by_class_name('js-lottery-date-pc') number = driver.find_elements_by_class_name('js-lottery-number-pc') for i in range(0,len(no)): backnumber = {} backnumber['回別'] = no[i].text backnumber['抽せん日'] = date[i].text backnumber['ナンバーズ3抽せん数字'] = number[i].text backnumbers.append(backnumber) backnumber_df = pd.DataFrame(backnumbers)
過去の当選番号をデータフレームに格納
#Webドライバーのタイムアウト時間を10秒に設定 driver.implicitly_wait(10) url = 'https://www.mizuhobank.co.jp/retail/takarakuji/check/numbers/backnumber/index.html' driver.get(url) backnumber_links = driver.find_elements_by_css_selector('.typeTK.js-backnumber-b tbody tr td a') links = [] for item in backnumber_links: links.append(item.get_attribute('href')) all_df = pd.DataFrame() for i in range(0,len(links)): url = links[i] driver.get(url) # HTMLテーブルを取得 df = pd.read_html(driver.page_source)[0] # append dataframe all_df = all_df.append(df, ignore_index=True) # ナンバーズ4抽せん数字の削除 all_df = all_df.drop(all_df.columns[[3]], axis=1)
全データを結合
df = pd.DataFrame() df = df.append(all_df, ignore_index=True) df = df.append(backnumber_df, ignore_index=True) # 空白行の削除 df = df.dropna(how='all')
CSVデータで出力して完成。

今回も、1時間ほどで抽出できました。 案件の単価が1万円〜2万円なので、受注できていたとしたら、いいお小遣いですね!
厚労省の介護情報サイトからPythonでスクレイピング

ランサーズに掲載されている「スクレイピング」関連の案件を、実際に受注したと過程してやってみようと思います。
今回はこちら
【1ヶ所のみ抽出】介護の情報データベースのサイトからのスクレイピングの依頼・外注 | Webシステム開発・プログラミングの仕事・副業 【クラウドソーシング ランサーズ】[ID:2593180]
依頼内容
静岡県内に特化した介護・福祉の求人サイトを運営しており、正確なデータベースが必要なので、「介護情報サービス」というサイトから静岡県内のみの「事業開始年月日」という項目をスクレイピングをお願いします。
スクレイピング対象サイトはこちらのようです。
見た感じ、そこまで難しくなさそう。 SPAだったので、seleniumを使ってスクレイピングしました。
スクレイピング
ライブラリをインポート
from bs4 import BeautifulSoup import requests import pandas as pd from time import sleep from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.select import Select import math
driverを起動、
url = 'https://www.kaigokensaku.mhlw.go.jp/22/index.php?action_kouhyou_pref_search_list_list=true' op = Options() op.add_argument("--disable-gpu"); op.add_argument("--disable-extensions"); op.add_argument("--proxy-server='direct://'"); op.add_argument("--proxy-bypass-list=*"); op.add_argument('--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36') op.add_argument('--no-sandbox') op.add_argument('--lang=ja-JP') driver = webdriver.Chrome('/Users/user/driver/chromedriver',options=op) driver.get(url) res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser')
# 最大ページ数を取得 dataNum = driver.find_element_by_class_name('allDataNum') post_count = dataNum.text post_count = post_count.replace('件','') max_page = math.ceil(int(post_count) / 50) # selectboxを操作 # 50件表示に変更 select_element = driver.find_element_by_id('displayNumber') select_object = Select(select_element) select_object.select_by_value('50')
最大ページ数をループさせてスクレイピング
all_data = [] for page in range(0,(max_page)): links = driver.find_elements_by_class_name('detailBtn') links.pop() link_list = [] for link in links: link_list.append(link.get_attribute('href')) for link in link_list: add_data = {} res = requests.get(link) soup = BeautifulSoup(res.text,'html.parser') startDateThTag = soup.find('th',string='事業開始年月日') startDate = startDateThTag.next_sibling.next_sibling.text title = soup.find('span',{'id':'jigyosyoName'}).text add_data['title'] = title add_data['startDate'] = startDate all_data.append(add_data) sleep(3) try: next_button = driver.find_elements_by_class_name('page-link') next_button[-1].click() except: print('error') sleep(5) driver.close() driver.quit() df = pd.DataFrame(all_data)
結果

CSVで出力することに成功しました。
作業時間だけだと、約1時間くらい。 あくまでも、CSVのデータ納品だと過程しての作業でしたが、、
1点うまく行かなかったのが、
Seleniumのwebdriverで、ヘッドレスモードにしたらうまく取得できなかった。 ユーザーエージェントを入れてもだめで、スクリーンサイズを指定してもだめだった。。
ちょっと原因不明なので、この件はまた別で調査することにします。 」
【Tableau】緯度経度で一定位置から範囲内のデータをフィルタさせるパラメータアクション

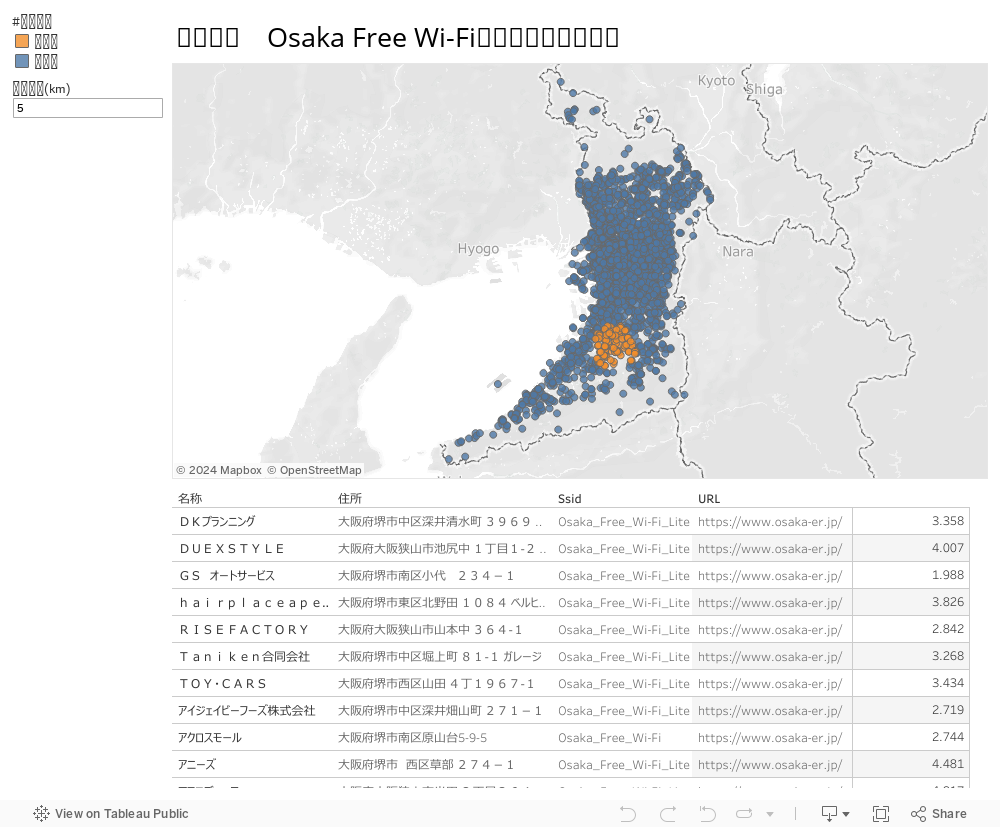
商圏分析をやる機会があったので、Tableauで実装する手段をまとめてみる
地図上のポイントをクリックすると、そのポイントから指定範囲内(画像では1km)のポイントに色付け 範囲内の事業所をフィルタリングして集計することもできる。
仕組みとしては、 カーソルを当てたポイントの緯度を「指定緯度」というパラメータに代入 カーソルを当てたポイントの経度を「指定経度」というパラメータに代入
ダッシュボードの「パラメータアクション」を作成し、 「指定緯度」と「指定経度」とそれぞれのポイントの距離を計算して距離に応じて色を変更する
サンプルVIZ
使えそうな緯度経度の情報がなかったので、ここではOsaka Free Wi-Fiのアクセスポイントを可視化してみた。
パラメータを作成
指定緯度、指定経度は、デフォルトの数値なので、登録するのはなんでもいい。

後から距離を指定できるようにしたいので、距離用のパラメータを作成。

計算式「距離」を作成
カーソルを当てたポイントの(緯度,経度)とそれぞれの(緯度,経度)の2つをmakepointでラップ、 DISTANCE関数で距離を求める
’m’や’km’の単位をここで指定する。
DISTANCE( makepoint([指定緯度],[指定経度]), [#makepoint], 'km' )
距離判定用の計算式の作成
IF [#距離] = 0 THEN '指定ポイント' ELSEIF [#距離] <= [距離指定] THEN '範囲内' ELSE '範囲外' END
それぞれのポイントが、範囲外なのかを判定する計算フィールド
距離のフィルタ
[#距離] <= [距離指定]
地図上のポイントをクリックしたら、他のシートにも指定範囲内でフィルタをかけたい。 上記のサンプルでは、WIFIのアクセスポイントの地図をクリックしたら、その範囲にあるアクセスポイントの詳細が下部分の表にフィルタリングされる。
パラメータアクションを作成
緯度、経度 それぞれのパラメータアクションを作成する。
クリックしたポイントの緯度経度で、パラメータを上書きする。


これで、マウスを当てたポイントから指定した距離範囲内のポイントについて色を変えることができる 指定した範囲内に存在する顧客数(患者数)を集計したり、商圏分析に利用できる。
BAFFAを使った可視化の方法とかは別途記事にしてみます。
【近傍分析】緯度軽度から指定範囲の場所を抽出する

Aテーブルにある緯度経度と、Bテーブルにある緯度経度を総当たりさせて、Bの事業所の半径250m圏内にあるA事業所を抽出したい。
geopyを使用
!pip install geopy
コード
import pandas as pd A = pd.read_csv('A.csv') B = pd.read_csv('B.csv') A_list = hp.values.tolist() B_list = ph.values.tolist() from geopy.distance import geodesic match_lists = [] for B_item in B_list: B_id = B_item[0] B_lat = B_item[1] B_lng = B_item[2] for A_item in A_list: match_list = {} A_id = A_item[0] A_lat = A_item[1] A_lng = A_item[2] bStation = (B_lat,B_lng) aStation = (A_lat,a_lng) dis = geodesic(bStation,aStation).m if(dis < 250): match_list['A_id'] = A_id match_list['B_id'] = B_id match_list['distance'] = dis match_lists.append(match_list) else: pass df = pd.DataFrame(match_lists)
ロジックは簡単で、単純にループで総当たりさせて、
geodesic(bStation,aStation).mで、2点間の距離をだした。
データフレームには、250m範囲の事業所が縦持ちで入っているので、商圏分析的に使用できる。
【K近傍法】scikit-learnでアヤメの多クラス分類(iris-dataset)
3種類のアヤメについて、それぞれ50サンプルのデータがあります。 それぞれ、Iris setosa、Iris virginica、Iris versicolorという名前で、全部で150のデータ。
4つの特徴量が計測されていて、これが説明変数。
- 萼片(sepal)の長さ(cm)
- 萼片(sepal)の幅(cm)
- 花びら(petal)の長さ(cm)
- 花びら(petal)の幅(cm)
アヤメの分類は3つのクラス
- Iris-setosa (n=50)
- Iris-versicolor (n=50)
- Iris-virginica (n=50)
特徴量から、それぞれの分類を予測していきます。
データ準備
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt import seaborn as sns sns.set_style('whitegrid') %matplotlib inline from sklearn import linear_model from sklearn.datasets import load_iris # データの読み込み iris = load_iris() # 説明変数をXに X = iris.data #目的変数をYに Y = iris.target iris_data = DataFrame(X,columns=['Sepal Length','Sepal Width','Petal Length','Petal Width']) iris_target = DataFrame(Y,columns=['Species']) def flower(num): ''' 数字を受け取って、対応する名前を返す''' if num == 0: return 'Setosa' elif num == 1: return 'Veriscolour' else: return 'Virginica' iris_target['Species'] = iris_target['Species'].apply(flower) # 1つのテーブルにまとめる iris = pd.concat([iris_data,iris_target],axis=1) iris.head()
特徴量を可視化
#pairPlot で可視化 sns.pairplot(iris,hue='Species',size=2)

plt.figure(figsize=(12,4)) sns.countplot('Petal Length',data=iris,hue='Species')

plt.figure(figsize=(12,4)) sns.countplot('Petal Width',data=iris,hue='Species')

ロジスティック回帰で予測
ここではロジスティック回帰による分類を簡単に実装してみる。
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split logreg = LogisticRegression() # テストが全体の40% X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.4,random_state=3) # データを使って学習 logreg.fit(X_train, Y_train) LogisticRegression() # 精度計算 from sklearn import metrics # テストデータを予測 Y_pred = logreg.predict(X_test) # 精度を計算 print(metrics.accuracy_score(Y_test,Y_pred)) 0.9666666666666667
0.9666666666666667 とかなり精度が高い。
次に、K近傍法で予測してみる
K近傍法で予測
K近傍法は英語で、k-nearest neighbor
学習のプロセスは、単純に学習データを保持するだけ。
与えられたサンプルのk個の隣接する学習データのクラスを使い、このサンプルのクラスを予測します。

★が新しいサンプル
これを中心に、 K=3ではAが1つ、Bが2つなので、分類されるクラスは、Bです。 K=6ではAが4つ、Bが2つなので、Aと判別される。
Kの選び方によっては、同数になってしまうことがあるので注意が必要な手法
# K近傍法 from sklearn.neighbors import KNeighborsClassifier # k=3 knn = KNeighborsClassifier(n_neighbors = 3) # 学習 knn.fit(X_train,Y_train) # テストデータを予測 Y_pred = knn.predict(X_test) # 精度 check print(metrics.accuracy_score(Y_test,Y_pred))
→ 0.95
# k=1にしてみる knn = KNeighborsClassifier(n_neighbors = 1) knn.fit(X_train,Y_train) Y_pred = knn.predict(X_test) print(metrics.accuracy_score(Y_test,Y_pred)) 0.9666666666666667
もっとも近いサンプルに合わせて分類すると精度が上がった
kの数値による予測精度の推移を見てみる
# 1~90まで繰り返す k_range = range(1, 90) accuracy = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, Y_train) Y_pred = knn.predict(X_test) accuracy.append(metrics.accuracy_score(Y_test, Y_pred)) # plot plt.plot(k_range, accuracy) plt.xlabel('K for kNN') plt.ylabel('Testing Accuracy')

kは増やしすぎても精度が下がる
こんな感じで、もっとも精度の高いところを選択するのが良さそう
【scikit-learn】ロジスティク回帰でアヤメの分類
前回、パーセプトロンによるアヤメの分類を行ってみました。
クラスを完全に線形分離できない場合は決して収束しないという問題点もあるため、ロジスティック回帰による分類を試してみた。
データ準備
import pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns from sklearn import datasets iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target print('Class',np.unique(y)) from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1,stratify=y) from sklearn.preprocessing import StandardScaler sc = StandardScaler() # トレーニングデータの平均と標準偏差を計算 sc.fit(X_train) #平均と標準偏差を用いて標準化 X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test)
ロジスティック回帰モデルのトレーニング
from sklearn.linear_model import LogisticRegression as LR lr = LR(C=100.0,random_state=1) lr.fit(X_train_std,y_train) # plot plot_decision_regions(X_combined_std, y_combined, classifier=lr,test_idx=range(105,150)) # plot label plt.xlabel('petal length std') plt.ylabel('petal width std') plt.legend(loc='upper left') plt.tight_layout() plt.show()

predictを出力してみる。
lr.predict_proba(X_test_std[:3,:])
array([[1.52213484e-12, 3.85303417e-04, 9.99614697e-01], [9.93560717e-01, 6.43928295e-03, 1.14112016e-15], [9.98655228e-01, 1.34477208e-03, 1.76178271e-17]])
1行目は1つ目のサンプルに関するクラスの所属確率 2行目は2つ目のサンプルに関するクラスの所属確率を表している
1行目でもっとも大きいのは0.853で、1つ目のサンプルがクラス3(Virginica)に属している確率を85.3%と予測している。
【scikit-learn】パーセプトロンでアヤメの分類を実装
今回は、パーセプトロンでアヤメの分類を実装していきたいと思います。
パーセプトロンとは
分類問題に使われる手法の一つで、いわゆる「教師あり学習」を行うためのもの。
「あるデータがどのグループに属するか」を学習して、未知のデータからグループごとに分類することができる。
「教師ラベル」といって、学習用データにはどのグループに属しているかという情報があらかじめ与えられていて、この「教師データ」を使って学習していきます。
パーセプトロンは、実はあまり使われていないらしく その理由としては
「与えられたデータが線形分離可能でなければアルゴリズムが収束しない」 という弱点があるかららしい。
線形分離とは、その名前の通りで「一本の直線で二つのグループに分離できる」ことです。 複雑な分類には向いていないのかなーと。
scikit-learnのirisデータセットを使って分類してみました。
アヤメのサンプルデータの準備
# import import pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns # import datasets from sklearn import datasets iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target # データセット分割 テストデータ30% from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1,stratify=y)
データの標準化
from sklearn.preprocessing import StandardScaler sc = StandardScaler() # トレーニングデータの平均と標準偏差を計算 sc.fit(X_train) #平均と標準偏差を用いて標準化 X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test)
トレーニングデータとテストデータの値を相互に比較できるように、標準化をしておく
パーセプトロンのインポート、学習
# パーセプトロンのインポート from sklearn.linear_model import Perceptron # エポック数40、学習率0.1でパーセプトロンのインスタンス作成 ppn = Perceptron(eta0=0.1, random_state=1) # トレーニングデータをモデルに適合 ppn.fit(X_train_std, y_train) # 予測 y_pred = ppn.predict(X_test_std)
accuracy_scoreで正解率を確認してみます。
# 分類の正解率 from sklearn.metrics import accuracy_score print('Accuracy: %.2f' % accuracy_score(y_test, y_pred)) # print('Accuracy: %.2f' % ppn.score(X_test_std, y_test)) score でもOK
Accuracy: 0.98 0.98?精度高すぎませんか?
決定領域をプロット
from matplotlib.colors import ListedColormap def plot_decision_regions(X,y,classifier, test_idx=None,resolution=0.02): # マーカーとカラーマップ markers = ('s','x','o','^','v') colors = ('red','blue','lightgreen','gray','cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # 決定領域のプロット x1_min, x1_max = X[:,0].min() - 1, X[:,0].max() + 1 x2_min, x2_max = X[:,1].min() - 1, X[:,1].max() + 1 # グリッドポイントの生成 xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution), np.arange(x2_min,x2_max,resolution)) # 各特徴量を1次元配列に変換して予測を実行 Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) # 予測結果を元のグリッドポイントのデータサイズに変換 Z = Z.reshape(xx1.shape) # グリッドポイントの等高線のプロット plt.contourf(xx1,xx2,Z,alpha=0.3,cmap=cmap) # 軸の範囲の設定 plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # クラスごとにサンプルをプロットする for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl,1], alpha=0.8, c=colors[idx], marker=markers[idx], label=cl, edgecolor='black') # テストサンプルを目出させる if test_idx: X_test, y_test = X[test_idx, :], y[test_idx] plt.scatter(X_test[:,0], X_test[:,1], c='', edgecolor='black', alpha=1.0, linewidth=1, marker='o', s=100, label='test set') # トレーニングデータとテストデータの特徴量を行方向に結合 X_combined_std = np.vstack((X_train_std, X_test_std)) # トレーニングデータとテストデータのクラスラベルを結合 y_combined = np.hstack((y_train,y_test)) # 決定領域のプロット plot_decision_regions(X=X_combined_std, y=y_combined, classifier=ppn, test_idx=range(105,150)) plt.xlabel('petal length [std]') plt.ylabel('petal width [std]') plt.legend(loc='upper left') plt.tight_layout() plt.show()
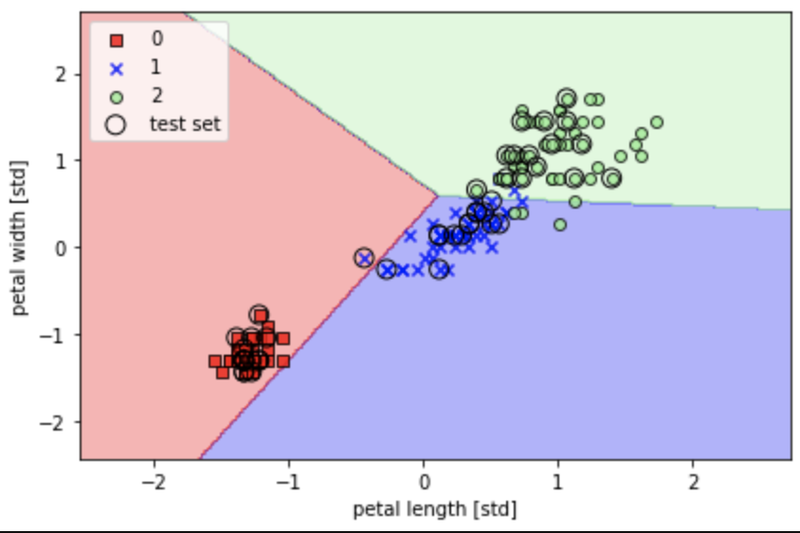
正解率は高かったですが、、
「3つの品種(多クラス)を線形の決定境界で完全に区切ることはできない」ということがわかりました。
今回はこのくらいにして、次回からはロジスティック回帰や決定木で分類してみたいと思います。